Together with SpaceXAI, we're training a significantly larger model from scratch, using 10x more total compute. With Colossus 2's million H100-equivalents and our combined data and training techniques, we expect this to be a major leap in model capability.
In my last article I covered the SpaceX(AI) IPO and the core strategy of the company (space, connectivity, and AI), highlighting that the company is pitching compute and intelligence for Enterprise applications to investors as the largest addressable market they have. If we look at the company's revenue today, however, they've been struggling to grow into "selling Grok to companies," particularly when compared to the massive demand that Anthropic and OpenAI are handling today.
As we gear up for the SpaceX IPO (likely ticker SPXQ; 6/12 launch), it's important to understand what the actual story is that Musk is trying to tell the market, and if executed well, how it would reflect on the rest of the industry.
The key to unlocking the market for them comes with the likely acquisition of Cursor, one of the early and most interesting winners in the developer tools space. Rather than limiting themselves to competing with the tens of coding harnesses currently on the market, they’ve been building in two directions that would allow them to scale: internally trained coding models and cloud.
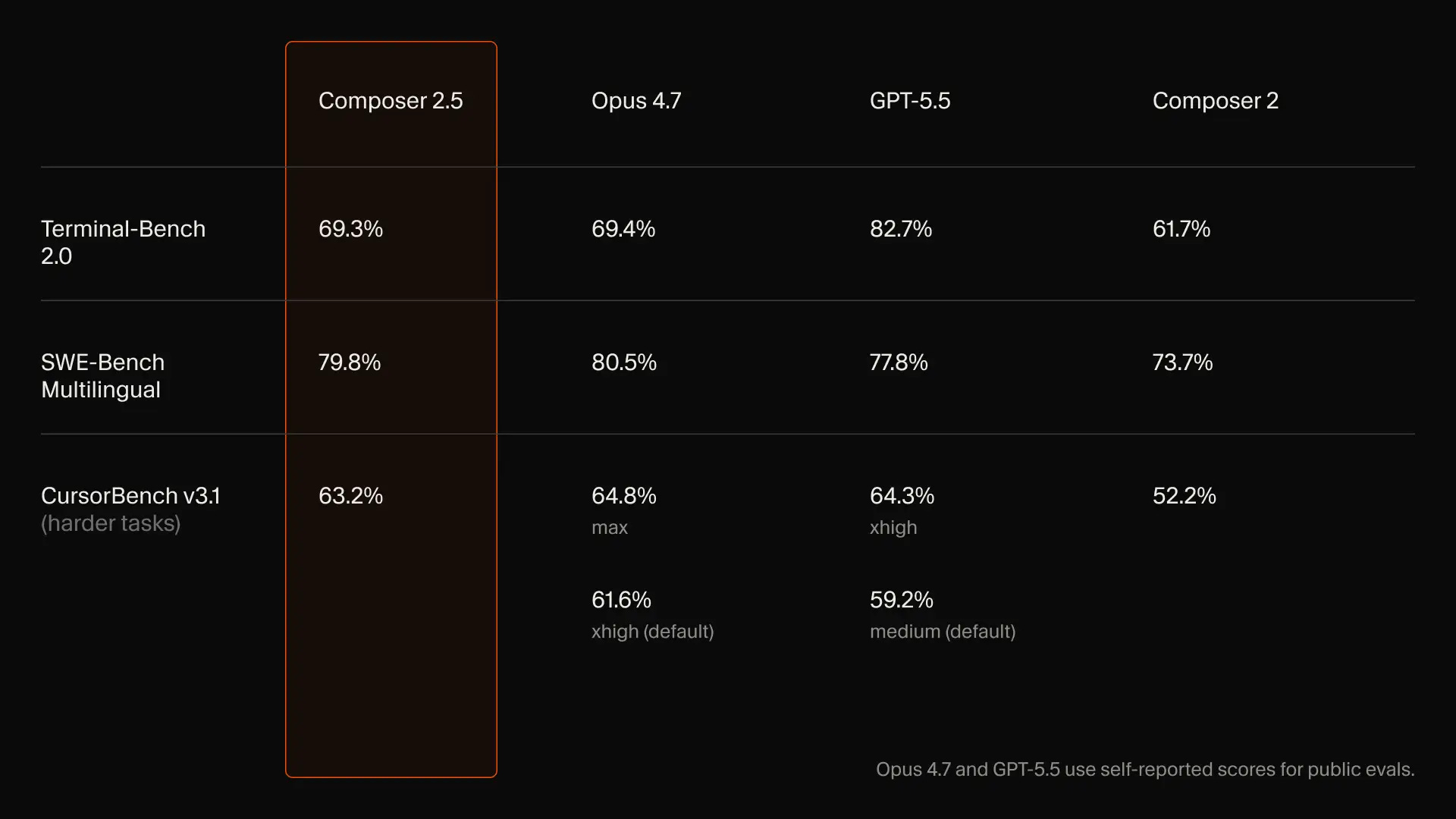
Source: Cursor blog
Targeted RL with textual feedback
Credit assignment during RL is becoming an increasingly difficult challenge as rollouts can span hundreds of thousands of tokens. When a reward is computed over an entire rollout, it may be hard for the model to tell which specific decision helped or hurt the outcome. This is especially limiting when we want to discourage a localized behavior, such as a bad tool call, a confusing explanation, or a style violation. The final reward can tell us that something went wrong, but it is a noisy signal for where it went wrong.
To address this, we trained Composer 2.5 with targeted textual feedback.1 The idea is to provide feedback directly at the point in the trajectory where the model could have behaved better. For a target model message, we construct a short hint describing the desired improvement, insert that hint into the local context, and use the resulting model distribution as a teacher. We use the policy with the original context as the student and add an on-policy distillation KL loss that moves the student’s token probabilities toward the teacher’s. This gives us a localized training signal for the behavior we want to change, while still retaining the broader RL objective over the full trajectory.
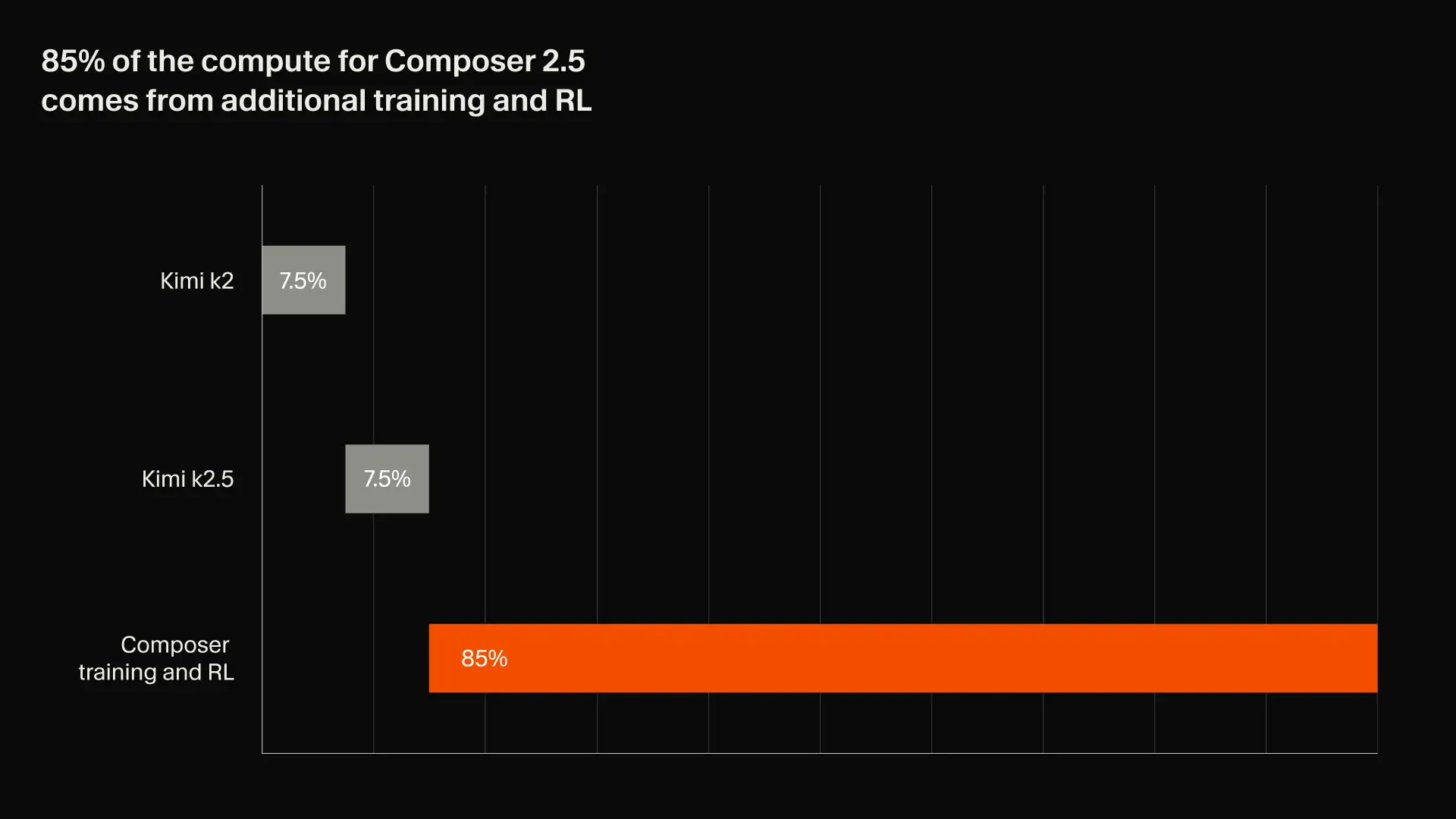
The funny thing about their coding model is that it’s picking up a well-performing open source model (in this case Kimi K2) and then they use their unique training data set to, as the kids would say, “rl the shit out of it.” This is not a magical pill, however:
Synthetic data
During RL training, Composer’s coding ability improves substantially to the point where it begins to get most training problems correct. To continue increasing intelligence, we both select for and create harder tasks dynamically throughout the run. Composer 2.5 is trained with 25x more synthetic tasks than Composer 2.
We use a range of approaches for creating synthetic tasks that are grounded in real codebases. For example, one synthetic approach is feature deletion. For these tasks the agent is given a codebase with a large set of tests, and asked to delete code and files in such a way that the codebase remains functional while specific testable features are removed. The synthetic task is to reimplement the feature, and the tests are used as a verifiable reward.
One downstream consequence of large scale synthetic task creation is that it can cause unexpected reward hacking. As the model became more adept, Composer 2.5 was able to find increasingly sophisticated workarounds to solve the task at hand. In one example, the model found a leftover Python type-checking cache and reverse-engineered the format to find a deleted function signature. In another, it was able to find and decompile Java bytecode to reconstruct a third-party API. We were able to find and diagnose these problems using agentic monitoring tools, but they demonstrate the increasing care necessary for large scale RL.
The team is getting more sophisticated, both by extending the training with synthetic data, as well as on how to approach the verifiable inputs during training. This is where the team is evolving from a “SaaS vendor playing around with model training” to doing genuine AI lab work to get improved outcomes.
Source: Cursor blog
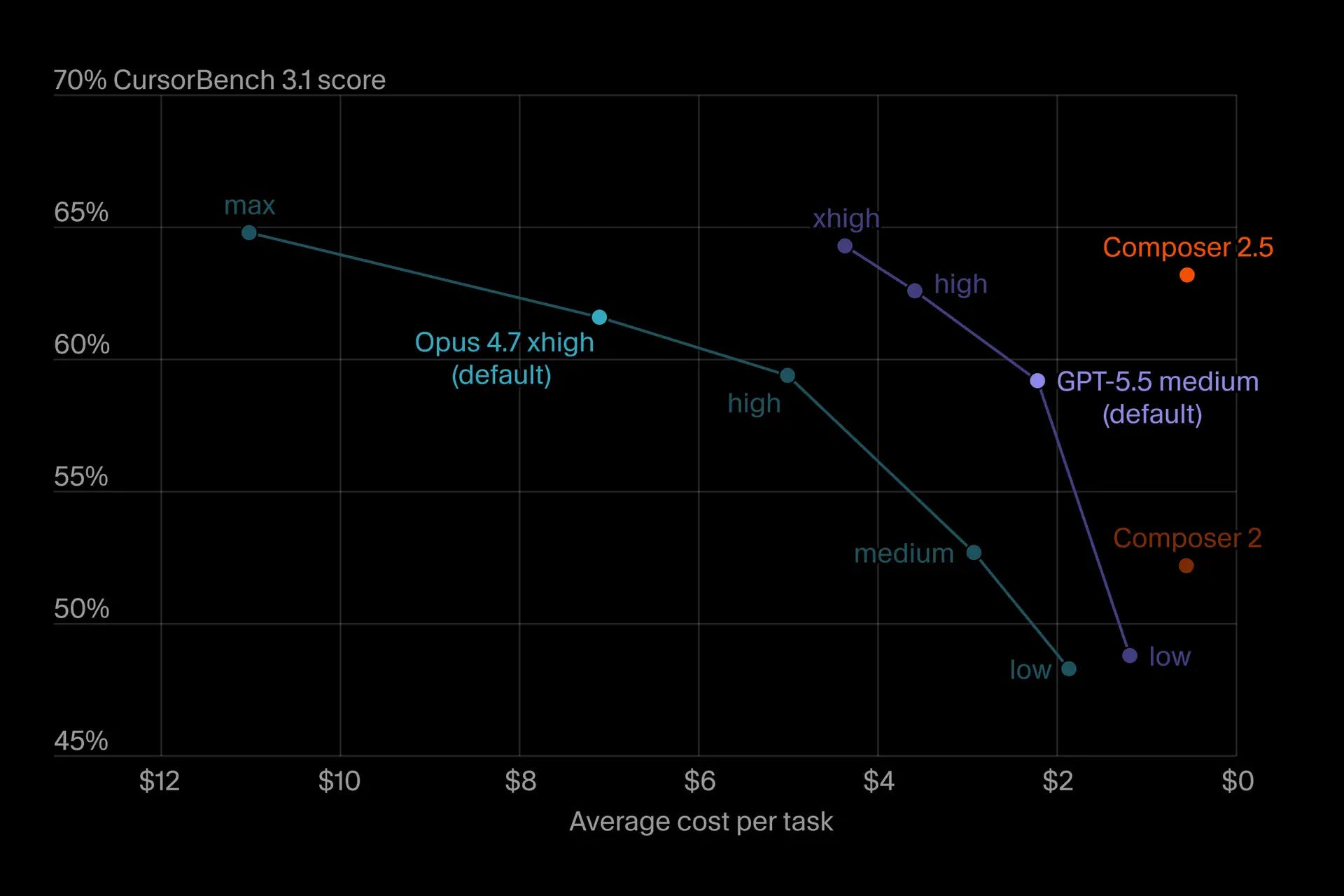
The end result is a model that's very competitive performance-wise, while being significantly cheaper than the "high" versions of either GPT 5.5 or Opus 4.7. Combined with the significant token generation speed, with Composer 2.5 the company has a genuinely interesting fit for Enterprises that are struggling with optimizing the running costs of their engineering teams.
For many companies that are adopting agentic coding at scale, Cursor as a product has been an interesting fit because it allows the team to rotate to different models that can easily shift their monthly cost significantly. If a company commits to a single provider (and receives minimal discounts because the sales teams at Anthropic and OpenAI currently barely offer any meaningful cost reductions), they run the risk of either overspending relative to the alternative models, or being left behind if one of the labs pulls ahead and delivers significant improvements.
This has been a big blocker for the xAI sales teams, as Grok has failed to be meaningfully competitive or cheaper, which means that most customers simply lacked the incentives to pursue any meaningful commits. Using Grok on-demand from the hyperscaler APIs was then the main source of revenue; however, that usage is fickle and easy to swap.
This is why the frontier labs are also trying to build out user surfaces that are "sticky," e.g. Claude Code, Cowork, Codex, etc. Cursor initially started with a relatively sticky surface (everybody was familiar with working with VS Code), but over time lost some of that advantage due to the move towards CLIs, as well as not offering a meaningfully differentiated experience. If anything, one of the big critiques of Cursor from a user adoption perspective was that the product was becoming too buggy and overcomplicated.
Agents are only as capable as the environment they run in. Without the ability to use the software they are creating, agents hit a ceiling.
Over the last few months, we addressed this internally by giving agents their own virtual machines with full development environments, and the ability to test their changes and produce artifacts (videos, screenshots, and logs) so you can quickly validate their work.
Today we’re making a new version of Cursor cloud agents available from anywhere you work, including the web, mobile, desktop app, Slack, and GitHub. Cloud agents onboard themselves onto your codebase and produce merge-ready PRs with artifacts to demo their changes. You can also control the agent’s remote desktop to use the modified software and make edits yourself, without checking out the branch locally.
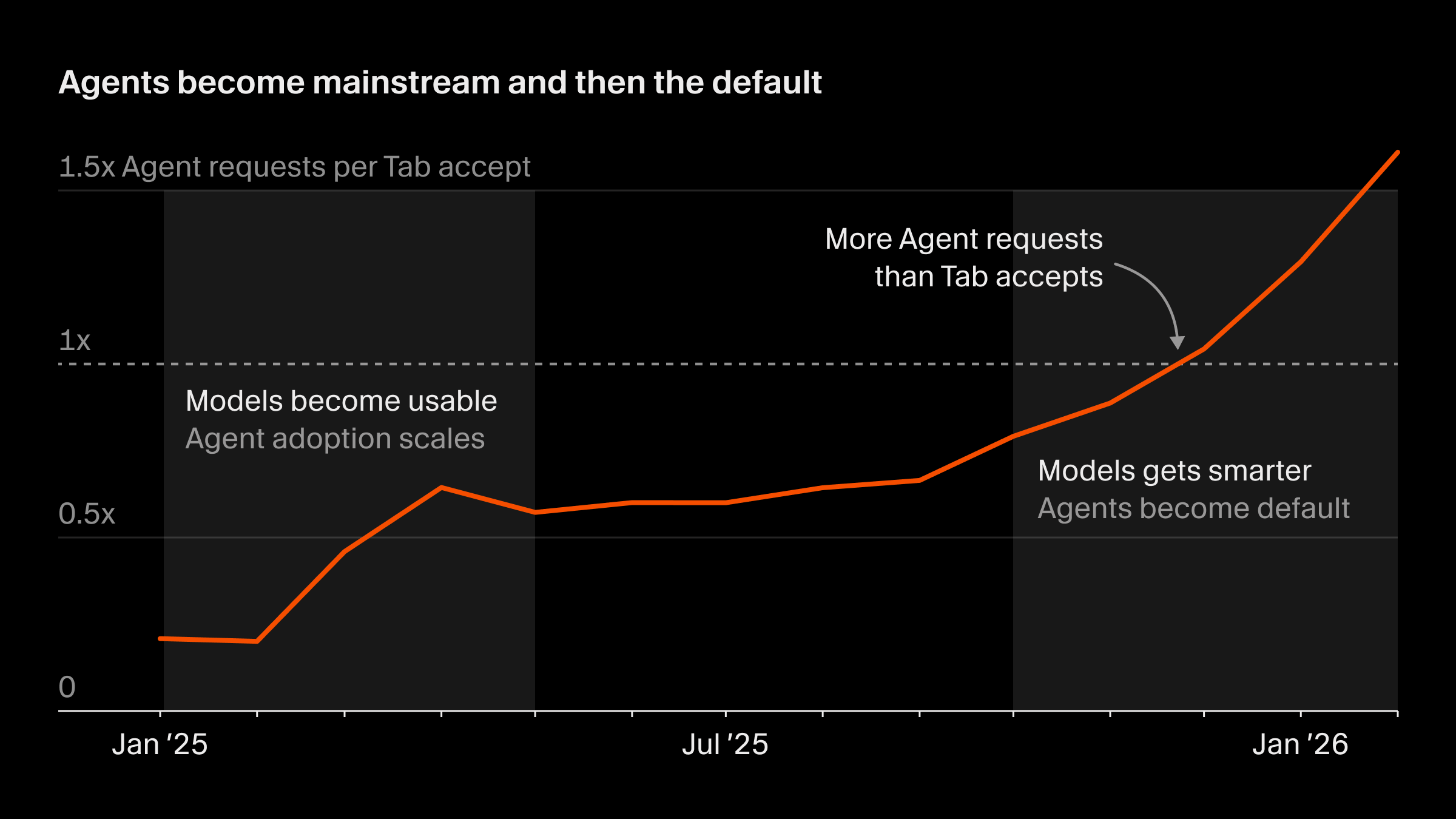
This has been the biggest shift in how we build software since the move from Tab autocomplete to working synchronously with agents. More than 30% of the PRs we merge at Cursor are now created by agents operating autonomously in cloud sandboxes.
The answer to this from the perspective of the company is to offer improved outcomes for engineers by giving coding agents virtual environments to test solutions and work on problems.
Using cloud agents at Cursor
For the last month, we’ve been using cloud agents internally, and it has changed how we build software. Instead of breaking tasks into small chunks and micro-managing agents, we delegate more ambitious tasks and let them run on their own.
These are a few ways we’re using cloud agents:
Building new features
We used cloud agents to help us build plugins, which we recently launched on the Cursor Marketplace. Here is one of our prompts:
For each component displayed in a given plugin’s page, we’d like to include a link to the source code. For skills, commands, rules, and subagents - that’s the .md file. For hooks, it’s the hooks.json. For mcps, it’s the .mcp.json or the manifest where it’s defined. As we index all the components of a plugin, keep track of the source file and construct links to that file by way of the underlying github url. Surface this to the frontend and have our frontend link out to github using this icon.
The agent implemented the feature, then recorded itself navigating to the imported Prisma plugin and clicking each component to verify the GitHub links.
For local testing, the agent temporarily bypassed the feature flag gating the marketplace page, then reverted before pushing. It rebased onto main, resolved merge conflicts, and squashed to a single commit.
Reproducing vulnerabilities
We kicked off a cloud agent from Slack with the prompt, “Please triage and explain this vulnerability to me in great detail,” followed by a description of a clipboard exfiltration vulnerability. When the agent finished running, it responded in the Slack thread with a summary of what it accomplished.
The agent built an HTML page that exploits the vulnerability via an exposed API. It started a backend server to host the demo page locally and loaded the page in Cursor’s in-app browser.
The video artifact shows the complete attack flow: the agent copied a test UUID to the system clipboard, loaded the demo page in Cursor’s browser, and clicked a button to exfiltrate and display the UUID. It also took a screenshot showing the successful clipboard theft and committed the demo HTML file to the repo.
While both Anthropic and OpenAI offer their own versions of agentic computer use, the Cursor implementation appears to be more widely adopted and can be seen as one of the key drivers behind their recent growth trajectory towards a $3B ARR run rate. Unlike the xAI team, the Cursor leadership and engineering teams are working towards a very opinionated version of what writing code will look like in the future:
What’s next
We’re building toward a future of self-driving codebases, where agents merge PRs, manage rollouts, and monitor production. We will go from a world where developers use agents to create diffs to one where agents ship tested features end-to-end.
To fully realize that shift will require improving tooling, models, and the interaction patterns. Our near-term focus is on coordinating work across many agents and building models that learn from past runs and become more effective as they accumulate experience.
The roadmap for Cursor actually fits quite well with some of the core products that xAI was trying to pursue before the recent reshuffle, when the majority of the research team left.
When we started building Cursor a few years ago, most code was written one keystroke at a time. Tab autocomplete changed that and opened the first era of AI-assisted coding.
Then agents arrived, and developers shifted to directing agents through synchronous prompt-and-response loops. That was the second era. Now a third era is arriving. It is defined by agents that can tackle larger tasks independently, over longer timescales, with less human direction.
As a result, Cursor is no longer primarily about writing code. It is about helping developers build the factory that creates their software. This factory is made up of fleets of agents that they interact with as teammates: providing initial direction, equipping them with the tools to work independently, and reviewing their work.
Many of us at Cursor are already working this way. More than one-third of the PRs we merge are now created by agents that run on their own computers in the cloud. A year from now, we think the vast majority of development work will be done by these kinds of agents.
If the team is able to deliver on the promise of “you can just hire our AI cloud engineers as your R&D team,” this has obvious advantages that many Enterprise customers might prefer to invest in. The lessons and operational competences at developing this for coding can then transfer into the “Macrohard” project, where xAI was trying to leverage computer use for a variety of white collar workflows.
Source: Cursor blog
I think that the vision is directionally correct and mostly impossible to achieve alone, at a time when OpenAI and Anthropic are pouring significant amounts of resources into a similar direction. The obvious choice for Cursor was to partner with either xAI or OpenAI, and given the price tag to acquire Cursor, it’s clear that Elon Musk went ahead and got the deal done.
Source: Cursor
Cursor has also been investing in their go-to-market strategy, both by building out an Enterprise-focused sales team and by running a significant number of DevRel events under the "Cafe Cursor" umbrella.
How the commercial teams will merge with xAI's existing hires is yet to be seen, although due to the recent wave of hires from playbook companies, it's likely that the integration will be rather quick. I think that they will benefit from keeping the Cursor branding and the developer-focused marketing, which so far has resonated a lot more than the existing Grok/xAI positioning.