
Why behind AI: Fables

The now infamous Anthropic model previously known as Mythos has finally arrived for public consumption, under the alias Fable 5.
I was intending to have this article be a test for the model and have it analyse itself in this format. Unfortunately for you, rather than reading the crisp thoughts of AGI, you’ll have to deal with me. I did flag it to the CCO of Anthropic, who was helpful about the issue.
Safety classifiers
The frontier cybersecurity and research biology capabilities of Mythos-class models mean that they pose a substantial risk of uplift to malicious actors. That is, these models could provide information or advice that assists those actors in causing serious harm that they couldn’t have received from other sources (for example, from internet search engines). Furthermore, a great deal of advanced usage of AI models is dual use: the same queries that are beneficial in the hands of cybersecurity professionals and biology researchers could be dangerous if available to malicious actors.
We therefore need strong safeguards to prevent misuse, and their coverage needs to be broad. The safeguards themselves have to stand up to sustained and sophisticated attempts to bypass them (also known as “jailbreaking” the system). The uplift from Mythos-level capabilities is valuable to many adversaries—for instance, those who could financially gain from cyberattacks—and we therefore expect them to be motivated to try to circumvent our safety measures.
Fable 5 comes with a new set of classifiers: separate AI systems that detect potential misuse, including jailbreak attempts, and prevent the main model (in this case Fable 5) from responding. We’ve been running classifiers on our models for some time, and Fable 5’s classifiers are an extension of this previous work with extra coverage.
When Fable’s classifiers detect a request related to cybersecurity, biology and chemistry, or distillation, the response is automatically handled by Claude Opus 4.8 instead. Users will be informed whenever this occurs. Opus 4.8 is a highly capable model in its own right: a response that falls back to Opus is a far better experience than an outright refusal from Fable. Our early data shows that more than 95% of Fable sessions involve no fallback at all—for those sessions, Fable 5’s performance is effectively the same as that of Mythos 5.
The following are the areas covered by the classifiers:
1. Cybersecurity. Mythos-class models excel at discovering and exploiting software vulnerabilities. They can thus make cyberattacks substantially easier and cheaper to commit. Mythos-class models also show strong skills in agentic hacking. This involves performing multiple different parts of a cyberattack in addition to finding exploits—reconnaissance, discovery, lateral movement, and more. To prevent these agentic hacking skills providing uplift in cyberattacks, we designed our cybersecurity classifiers to cover both exploitation and offensive cyber tasks in a broader sense. As shown in the graph below, our classifiers prevent Fable from making any progress on these tasks.
…
2. Biology and chemistry. We have long used our classifiers to block our models from responding on a narrow selection of bioweapons-related queries. But we are no longer certain that blocking this narrow selection is enough. This is for two reasons: first, we have reason for concern about well-resourced malicious actors attempting to gain uplift from our models for highly risky biological research. Second, models now have a greater ability to accomplish real-world scientific tasks.
While on paper this sounds logical, users are reporting many queries being blocked, particularly based on user history. Most actual professional biologists are basically unable to use the model, even if part of pre-approval programs. It appears that a similar issue is playing out across offensive cybersecurity professionals.
The reason why my queries got blocked is because it appears that the model also is avoiding any workflows that might lead to training other models, i.e. asking it to analyse its scorecard is considered material risk. The day after the launch it was reported that some of these safeguards will have to be walked back, particularly those blocking any ML/AI work by external researchers.
For a small group of cyberdefenders and infrastructure providers, we’re also launching Claude Mythos 5. It’s the same underlying model as Fable 5, but with the safeguards lifted in some areas.2 Mythos 5 will initially be deployed through Project Glasswing, in collaboration with the US government, as an upgrade to Claude Mythos Preview. It has the strongest cybersecurity capabilities of any model in the world. Soon, we intend to expand access to Mythos 5 through a broader trusted access program.
It’s important to note that Fable 5 is essentially Mythos with significant blockers around its best capabilities. Mythos is not being released to the public, but only to a small selection of companies, creating a “two tier” lane where large corporations and public sector organizations will have access to the best models, while the rest will be limited by design.
Availability
Claude Fable 5 is available everywhere today. Claude Mythos 5 is restricted to Glasswing partners (with cyber safeguards lifted) and soon to select biology researchers (with biology and chemistry safeguards lifted) only, until our broader trusted access program is available.
Pricing for both models is $10 per million input tokens and $50 per million output tokens. Developers can use claude-fable-5 via the Claude API.
We expect demand for Fable 5 to be very high, and difficult to predict. On the Claude API and consumption-based Enterprise plans, Fable 5 is fully available from today. For subscription plans, we’d rather give access sooner than later, so we’re rolling out more conservatively, in stages:
From today through June 22, Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost.
On June 23, we’ll remove Fable 5 from those plans. Using it after that will require usage credits. If capacity allows, we’ll extend the included window.
After this point—when sufficient capacity allows us to do so—we aim to restore Fable 5 as a standard part of subscription plans. We intend to do this as quickly as we can.
While limiting the release of Mythos to the public is a hard fork, the pricing model represents a soft one. While Fable 5 is temporarily available as part of regular subscriptions, usage will shift to API access only after 6/22, and allegedly will be restored at some point if there is enough compute (there is never going to be enough compute).
From a product design perspective that’s not a lot of friction (users can toggle on demand billing with a single click in the interface and still keep working in their browser/desktop app). What is more likely to happen is that very few “civilians” will end up using these levels of models on a daily basis once the hard reality of the token cost comes into play. I wrote the following on X about testing Fable 5 in an Enterprise context:
While X has been on fire in the last 24 hours with influencers and power users sharing their experiences with the latest Anthropic model, most of it has been limited to coding or “difficult problems”.
Anthropic is generating tens of billions of ARR predominantly from Enterprise usage. A lot of it is from coding, but there is a significant portion driven by users adopting Cowork as a job companion. Cowork was mostly ignored by the X power users because most of them do not actually work directly with Enterprise customers, where they need to present, analyse and deliver on outcomes under deadlines and with millions on the table.
I’ve been using AI heavily for Enterprise work for a while, but mostly in the context of deep research reports and accelerated learning in complex technical or industry domains. Similar to coding, I expected to see progress of the models being useful for translating this domain knowledge and analysis into more “practical” deliverables, but I found it mostly lacklustre.
Two months ago I started using Cowork also for building out presentations with the Opus models. It’s okay, but I would rate it as having a junior employee doing a barely passable job at it, rather than a meaningful differential. Opus (and Anthropic models in general) have had spotty performance in the last months, mostly driven by what I perceive as dynamic performance reductions based on available compute, combined with aggressive testing of efficiency algorithms in production.
I don’t think that the Anthropic team is “dumbing down” models on purpose, but they have significant constraints vs their $60B ARR of inference currently being used. This results in difficult choices with tradeoffs that make the experience for power users worse. The net effect is that while using Opus in Cowork helps me reduce the hours needed to get to a great presentation, I’ve often ended up spending $15 bucks (the average cost) to get an average deliverable, which I would end up using almost nothing from but at least it helped me clarify what I really wanted to show and how to position it.
I spent most of today working on a difficult pitch to a customer that wants to cut costs aggressively for a renewal. They are in financial services and running a complex platform that has internal cost pressures. The real work will be going there in person and convincing them to change how they work, but to get to that point I need enough bait to convince them to take this seriously.
Mythos costs approximately double the Opus rate card (which is not a guarantee for the real running usage due to token consumption) but in this case it ended up exactly 2x my typical presentation bill ($30 bucks in magic API tokens).
Unlike Opus however, it actually delivered a fully usable transformational pitch, based on their full real life context. Typically when I feed a lot of documents to Opus, it fails to actually transform these into insights for a presentation. Here it delivered a full:
Intermediate level slide deck
Value assessment model
Internal strategy doc that makes sense
Most of the power users on X will lose access to Mythos/Fable on June 22. Some of them will keep paying the API costs or will use it in other coding tools where they are paying for usage, but in general they will not keep trying complex problems with it.
I’m also a heavy user of Codex and GPT Pro models. Mythos is a proper competitor to GPT Pro and in the context of Enterprise work, it’s better since it produces better materials with its implementation of computer use.
I think that for OpenAI to seriously challenge back Anthropic in the Enterprise market, they have to deliver a similar type of experience. The problem they have is a traditional network effects and distribution advantage risk - many companies are diverting their spend towards Anthropic and will not churn from month to month due to the pendulum swinging in the other direction.
xAI and the Cursor team also have a limited window to enter this conversation, but realistically speaking they will likely only be able to compete on cloud coding agents use cases (which is still worth hundreds of billions in market value).
Google, the proud owner of DeepMind and Workspace should be owning this category and workload. Their failure to compete here should’ve cost several C-levels their roles.
Microsoft also had a significant moat here which was quickly destroyed due to complete lack of vision and product execution.
Mythos/Fable is strong for Enterprise workloads. The next big training run is probably going to be the actual “white collar AI layoffs” trigger. I have no reason to hire junior employees anymore based on what I can get out of $30 investment.
I’ve repeatedly talked about the idea that the “permanent underclass” is a very likely outcome because the top performers using best-in-class AI are likely to deliver the productivity and impact of literally tens of FTEs. Historically, this type of leverage has been driven by elevating top performers to “strategic” senior management roles, where they can set the direction and the org structure below them goes and executes. Since the average productivity of that org structure is not particularly high, we have a lot of FTEs spending a lot of hours on singular deliverables - a product demo, a filled out vendor questionnaire, a presentation. Capable enough AI models collapse this output on behalf of the top performers, who typically have the “final say” over the messaging and content structure anyway.
This is why we’ve seen “AI-native” companies of high growth deliver exceptional revenue per employee compared to supposedly best-in-class large corpos with massive distribution and capital advantages. In my example, if I want to scale my team, it’s smarter to get one other FTE that’s on a similar capability level as me + a large token budget, than 3 other FTEs that will waste a lot of time and require significant supervision in order to get to essentially the same outcome.
It’s not surprising that Dario’s return to blogging happened the day after the Fable 5 launch, in order to argue over government policy:
2. Macroeconomics and tax policy
Governments have long faced the problem of how to encourage economic growth while also providing important public services and ensuring that the least fortunate are taken care of. An important (and generally correct) premise of these debates has been that economic growth is fragile and difficult to achieve—that while reducing inequality might provide important benefits, it has to be traded off against the economic drag of increased taxes or deficits.
I suspect that powerful AI may scramble this assumption. If AI achieves the ability to do most cognitive tasks far better than humans, it stands to reason that it could result in extremely rapid and robust economic growth via the acceleration of science, technology, and operational efficiency. The iterative ability of AI to build even better AI may supercharge that growth even further. But for exactly the same reasons, AI may also act as a more general economic substitute for human cognitive abilities than previous technologies have, while also altering the economy far faster than previous technologies have. Thus, it’s reasonable to think that AI could produce much larger disruptions to the labor market than previous technologies, and, potentially, more enduring disruptions. We risk ending up in a world where the economic tradeoff dial is stuck on the hypergrowth, hyper-inequality setting, and is potentially very hard to unstick from that setting. The key challenge in such a world won’t be incentivizing growth, but finding a way for everyone to share in the benefits.
Of the topics discussed in this essay, macroeconomics and enduring labor displacement are arguably the ones that have attracted the most public attention and the most misunderstanding, so I want to be extremely clear on two points.
First, enduring job displacement is undesirable and dangerous, and we should do everything we can to minimize or prevent it, not to bring it about. I have warned about job displacement in interviews and essays because I want both policymakers and the private sector to have the best chance to adapt and respond, not because I am trying to be a “prophet of doom”. As a company, Anthropic always does as much as it can to work with customers to find creative new use cases and new sources of revenue that allow them to do more with their existing workforce, rather than focusing solely on cost savings (which often means reducing the workforce). We also constantly try to think of new interaction paradigms that allow humans to have as active a role as possible in collaborating with AI systems as those systems advance. More broadly, it is valuable for the whole world to experiment with using AI in as many new ways as possible, as that is the way for society to discover new possible job configurations. I do think AI will enable a number of new economic opportunities. I’ve predicted that AI will enable single individuals to create billion-dollar companies, and we’re already seeing teams of only a few people build businesses with hundreds of millions in revenue. But at the same time we should recognize that there’s a decent possibility that, despite all our efforts, AI still causes significant enduring job loss—and that this may be an intrinsic property of the technology and the way it broadly replicates human cognition4
Second, any response to AI-driven job displacement needs to address both the need to provide for everyone economically, and the need for people to find meaning, purpose, and agency. The latter is ultimately more important, and it depends on deep questions about how society is organized, what people should strive for, and what constitutes the good life. I am actually very optimistic that, even in a world with AI’s that are better than everyone at everything, humans can live lives of deep purpose and strive to build awe-inspiring and beautiful things5
But this is something to be collectively worked out by society as a whole, not something policy can directly address. Policy can be most helpful in buying us time to do that work, by slowing down job loss and providing economically for those likely to be affected.
In that spirit, some key policy interventions that are likely to be helpful include:
Measurement and tracking. It’s easy to dismiss mere data collection and analysis as inadequate to the scale of the problem, but we are unlikely to get good policy if we cannot accurately measure what is happening on the ground. Anthropic has been operating an Economic Index of how people use Claude for nearly a year and a half, but governments have access to types of data we do not, and could greatly expand their economic statistics to more carefully track AI job displacement.
Pro-employment incentives. A wide range of pro-employment policy incentives can help to slow or reduce job displacement, including: wage insurance policies that compensate people when they have to take a lower-paying job6, retention tax incentives to encourage employers not to make layoffs, workforce training grants, or infrastructure to facilitate matching of employers to employees to speed the rate of labor market adaptation. While the particulars of which interventions are best will depend on what kind of labor displacement AI brings, we should readily accept the costs and market inefficiencies that these policies could entail, particularly as they are likely to be offset by AI-driven productivity gains.
Long-term macroeconomic support. If AI-driven labor displacement ends up being large in magnitude and permanently drives down the demand for labor, it will likely be necessary to go beyond mere incentive programs to long-term income support for a significant fraction of the labor force. Mechanisms such as universal basic income could be financed through taxes on relevant companies or raising the capital gains tax. Universal capital accounts offer another vehicle. Broadly speaking, fast economic growth should create the tax base for shared prosperity.
A common focus of economic concern about AI that I haven’t mentioned has been datacenters and particularly their potential to raise energy prices. My view is that AI companies should pay to absorb rate increases—and Anthropic has already made a pledge to do so—but I see public hostility to datacenters as largely a symbol or outlet for broader economic anxieties about AI. It is important we have a direct societal conversation about these wider economic issues and truly have compelling solutions for them, or else they are likely to manifest indirectly, as they have with datacenters.
“It’s time to take Universal Basic Income seriously, y’all” is quite the pitch directly after launching Fable 5.
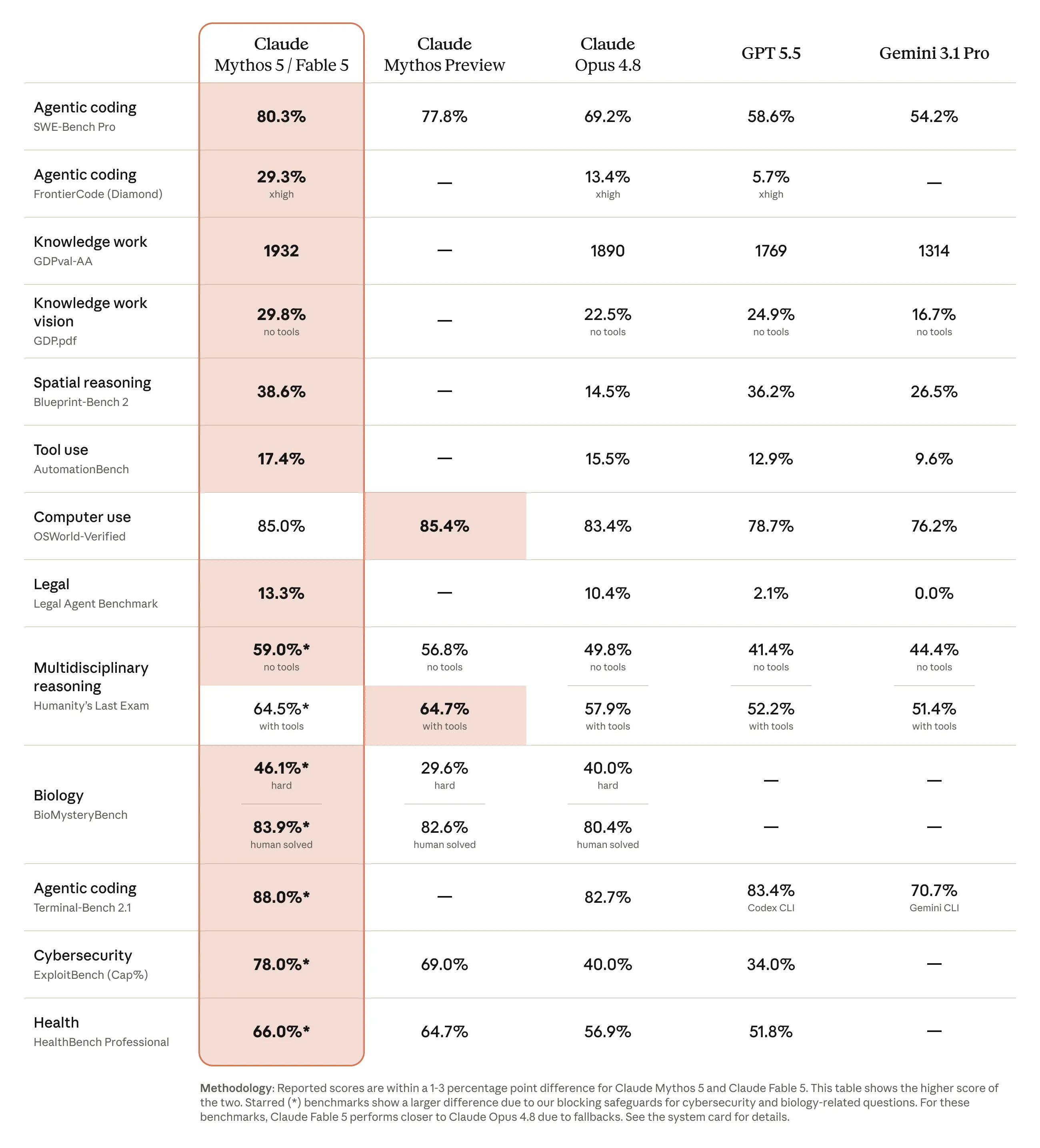
So how does Fable 5 benchmark? On paper, it's the strongest model in the world. When using it to work on my own applications, it's the first Anthropic model in a while that GPT 5.5 xhigh has no fixes to do. In my experience, since the launch of Codex, the best model to use from end to end to deliver an application has been from OpenAI. When using Claude, there was always something that's not done properly, introducing either bugs or security risks or the functionality just doesn't work. The GPT models running on their highest token budgets were my "senior dev fixing it". Not anymore with Fable (not that my actual usage will change here, as using the $100 subscription from OpenAI covers significantly more coding and analytical workloads than using the same $ value via on-demand tokens with Fable 5).

I think that the best way to think of these models is not that you are suddenly speaking to the highest intelligence in the universe, but that it actually completes fully the challenges you throw at it. My biggest issue with Anthropic models in recent months is that you are almost always guaranteed a significant mistake or wrong conclusion the more complex the conversation gets. This “selective stupidity” is likely driven by the efficiency design of older training runs combined with aggressive compacting of the context window. It’s not that Opus was not capable of strong insights, it’s more that they would be sporadic because somehow it keeps forgetting critical information even if given to it earlier in the conversation.
At least in this first week of the launch, Fable doesn’t seem to have these issues. It also seems to perform at a similar cognitive level to GPT 5.5 Pro, which is essentially the only model I use for day-to-day conversations that require deeper thought. Keeping in mind that it’s a cheaper model (on paper, the prompts via the OpenAI subscriptions are very generously subsidized), this is a significant win.
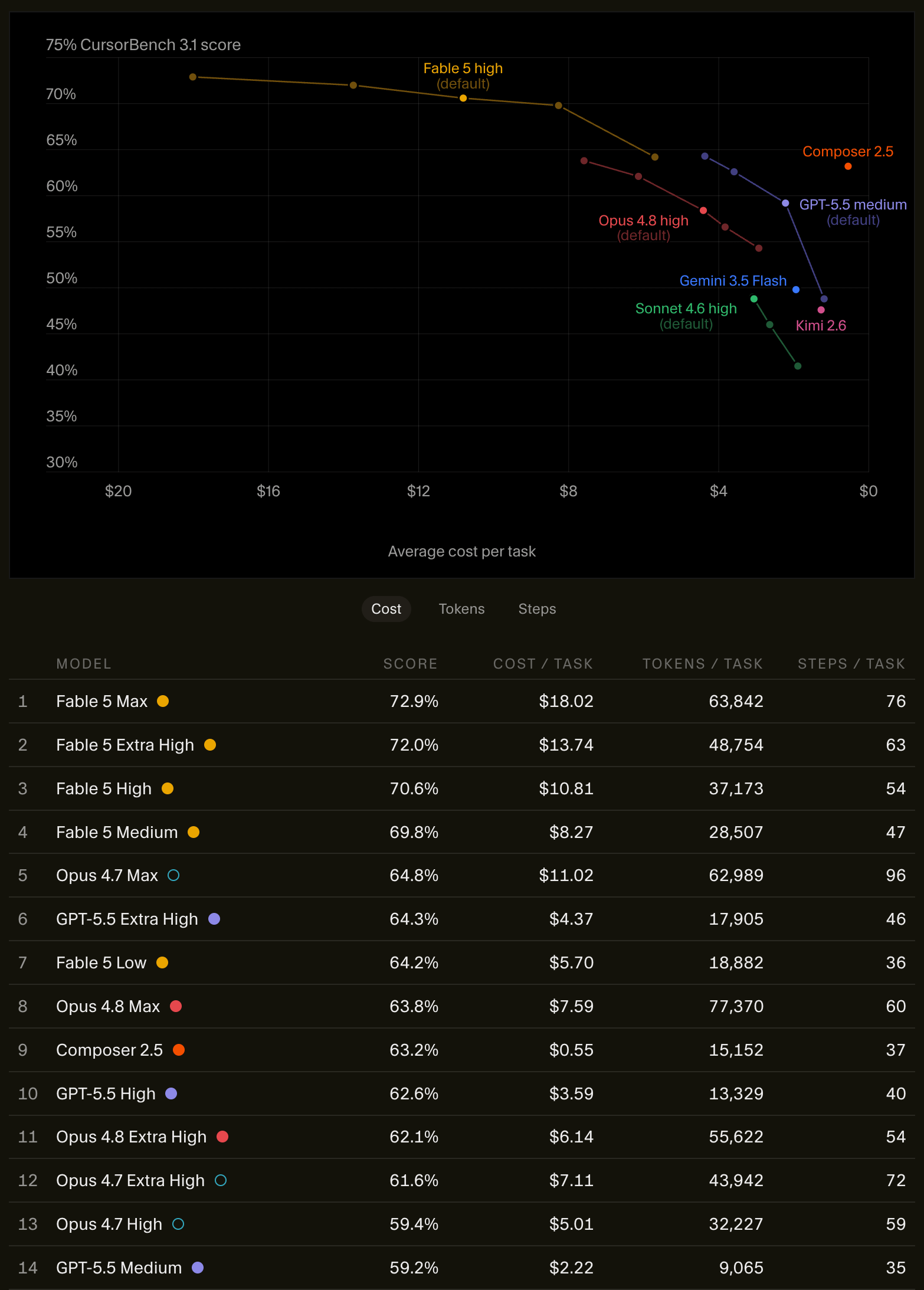
The Cursor benchmark paints a similar picture, where interestingly enough Fable 5 low is competing at the same performance level as 5.5 xhigh, albeit at almost double the dollar value in token usage.
What happens next? I think that the compute availability and pricing issue remain the biggest issue for scaling usage. I would expect the majority of token use for Fable 5 to remain in Enterprise for users that have significant token budgets per employee. I think that the model is the strongest “average productivity companion” currently in the market, albeit it does require actual results to be delivered with it in order to justify the investment.