
Why behind AI: Benchmaxxing
On real and perceived improvements in frontier models

The sentiment around AI seems to be mostly negative for your average person, mildly enthusiastic for your typical corpo worker, and conflicting for the “terminally online.”
While progress in the last two years has been rapid, for those that are trying to get an edge by adopting the latest models at launch, it’s been difficult to easily understand “how well” we’ve progressed. Benchmarks have served as a relative proxy for progress by visualizing the gaps between models and indicating directional usefulness. When users actually leverage models in their daily workflows, however, those supposed differences are rarely clear and, more often than not, misleading. Users vote for real utility by focusing their token spend only on the actual top performers.
DeepSWE is a long-horizon software engineering benchmark that delivers four major advances over today’s public benchmarks:
Contamination free: Tasks are written from scratch, not adapted from existing commits or PRs, so no model has seen the solution during pretraining.
High diversity: Tasks span a broad pool of 91 repositories across 5 languages.
Real-world complexity: Prompts are half the length of SWE-bench Pro’s, yet solutions require 5.5x more code and ~2x more output tokens.
Reliable verification: Verifiers are hand-written to test software behavior rather than implementation details.
Existing benchmarks fall short on several of these axes. SWE-bench Pro, the leading agentic coding benchmark, has tasks averaging just 120 lines of code to solve, and our audit found its verifier misgrades agent outputs at rates of 8% false positives and 24% false negatives. Frontier labs are also raising growing concerns about benchmark contamination.
By contrast, DeepSWE produces a sharper comparison of frontier coding agents. Models that appear close together on public benchmarks separate into wide, ordered gaps that match the differences developers see in day-to-day agent workflows.
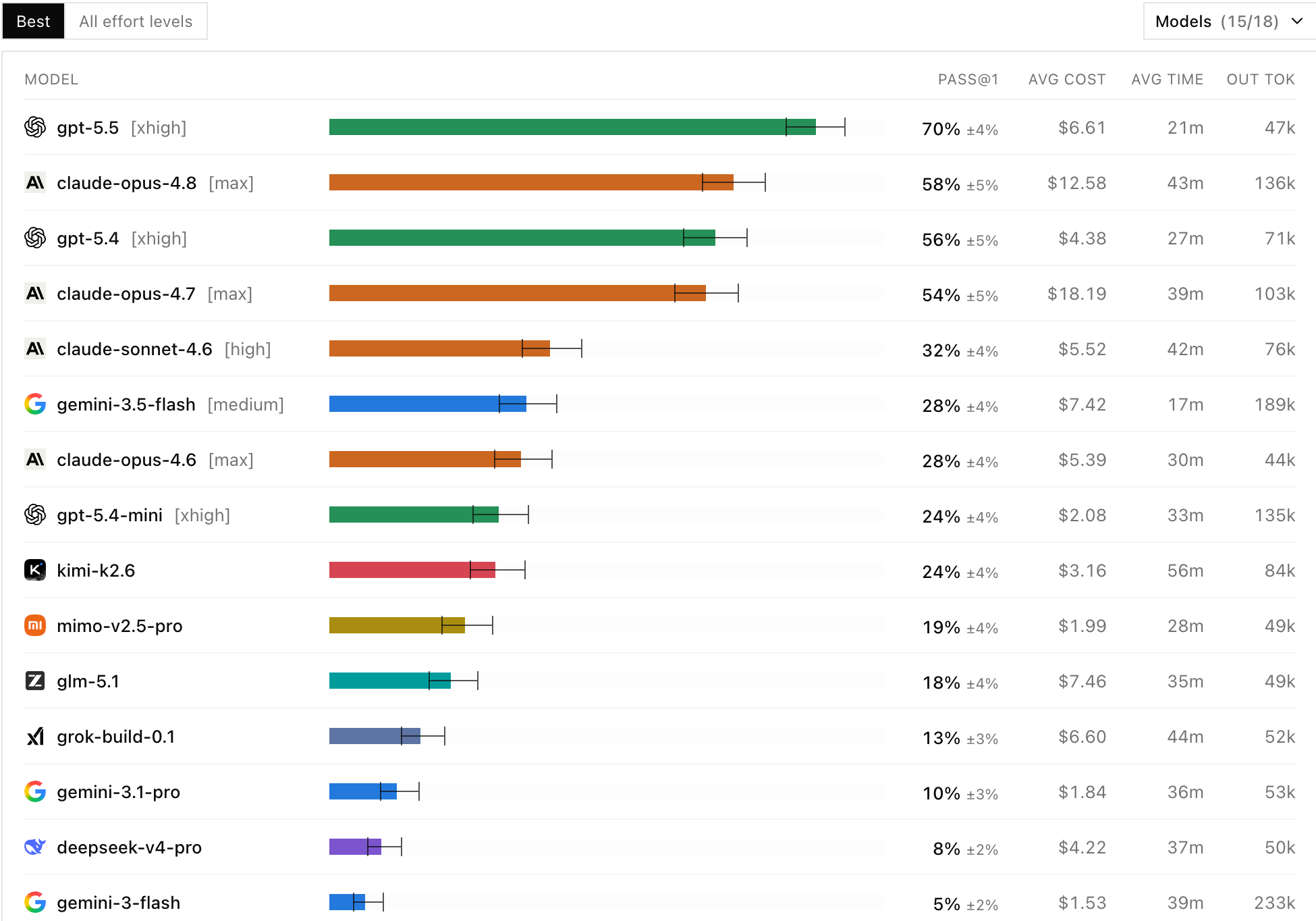
The team at Datacurve has come up with a new benchmark they call “DeepSWE,” which appears to be quite a good reflection of how models today “feel” in terms of performance, rather than purely how they benchmark.
1. Long-horizon work, realistic and short prompts
DeepSWE prompts are aligned with the way developers talk to their agents: behavior-focused, short, and free of large interface-definition blocks, rather than overly verbose and prescriptive. Agents must discover where and how to implement the change, so a substantial share of the capabilities being evaluated involve end-to-end exploration instead of just the execution of an overspecified engineering task.
Public benchmarks sourced from GitHub issues and pull requests often carry more detail: reproduction steps, additional context, code snippets, and tests that assume specific symbols or signatures. DeepSWE instead scores observable behavior, which lets prompts stay short and natural even when the underlying tasks are substantially longer.
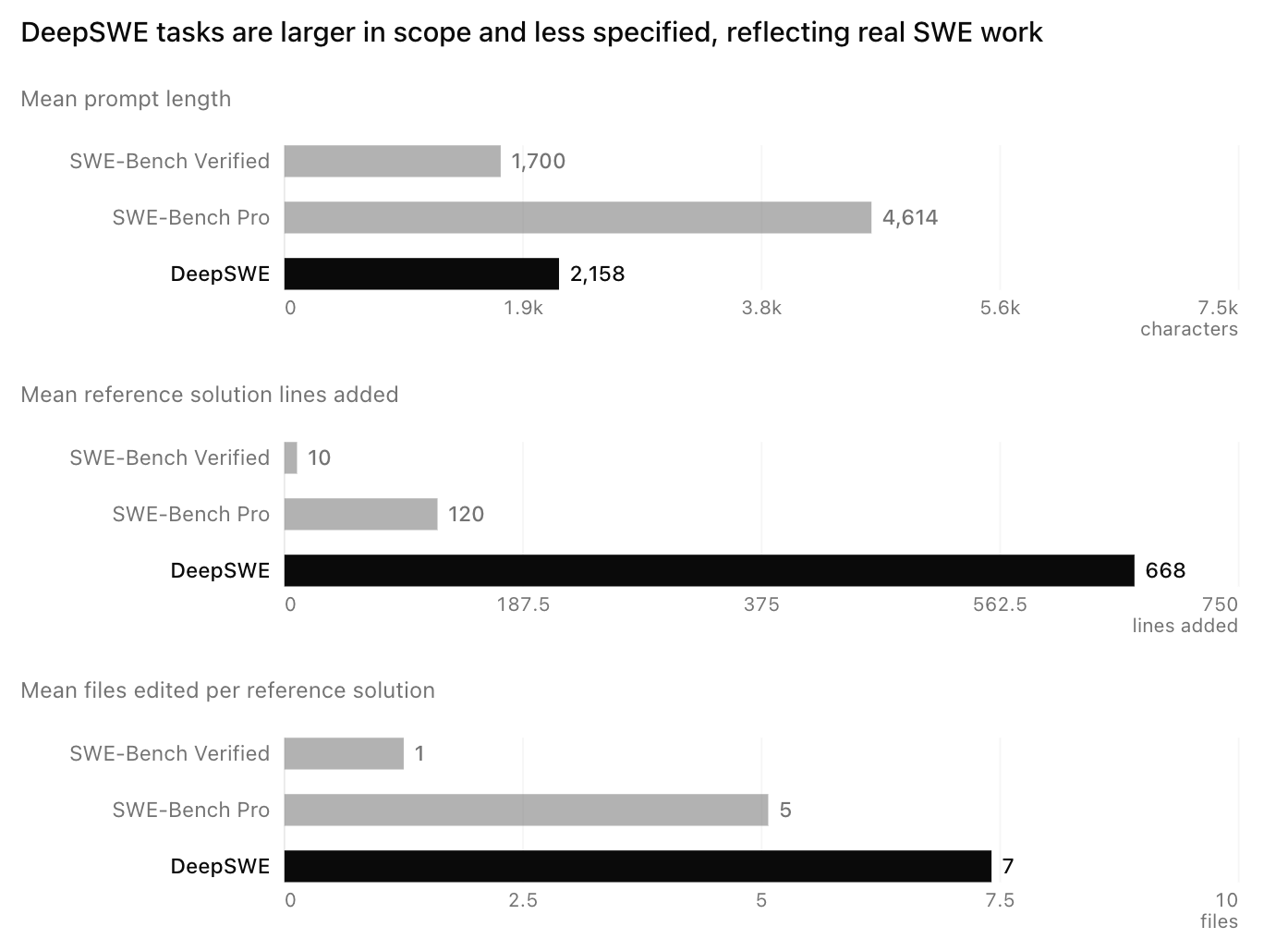
Most benchmarks today are actually very scripted and specific. This made sense in the early stages of agentic coding due to a lack of optimization for software development tasks, but things look quite different nowadays. Nobody spends time on basic direction like “you can use this tool, ensure you open it this way,” but instead focuses on back-and-forth around the practical outcome.
2. Broad repository coverage
DeepSWE contains 113 tasks spanning 91 active open-source repositories across 5 languages: TypeScript, Go, Python, JavaScript, and Rust. Sampling at this scale makes DeepSWE a much stronger proxy for the real-world utilities of coding agents: whether they can make useful, well-scoped changes across varied codebases with different levels of structure, documentation, and maintenance.
Existing public benchmarks are much more concentrated. SWE-Bench Pro Public spans 11 repositories, and SWE-Bench Verified spans 12, with many tasks drawn from prominent, heavily maintained projects. That is a narrower setting than the range of projects developers bring to coding agents in practice.
An issue with current benchmarks is that they often cover “known” issues. In practice, this means many of the new models are optimized for these challenges because either the problem is already solved in their training data or the models “cheat” by looking up the real code used to solve the problem.
3. Novel tasks test problem-solving, not recall
Every DeepSWE task is original: the reference solution is written from scratch rather than copied or adapted from an existing pull request, commit, or public patch. Some tasks are motivated by unresolved GitHub issues, but the fix itself is new. DeepSWE tasks are also never merged back into the upstream repositories, so they do not enter the public GitHub record and are unlikely to appear in future pre-training corpora scraped from open source.
This makes DeepSWE a cleaner test of whether an agent can solve a novel software engineering problem, rather than recall, retrieve, or rediscover a public fix.
Benchmarks sourced from existing commits have an inherent contamination risk because its corresponding implementation, tests, and discussion are already online. Our SWE-Bench Pro audit found that this risk is not hypothetical, with solution leakage and false positives affecting roughly 8% of audited rollouts.
The real challenge today in benchmarking how models are progressing on software engineering tasks is their ability to solve novel problems, not to act as a glorified wiki for previously used code. This is why one of the first tests power users typically run is to ask the models to create an application for them, and they keep comparing how different models are able to execute on it, rather than how well they are benchmaxxing.
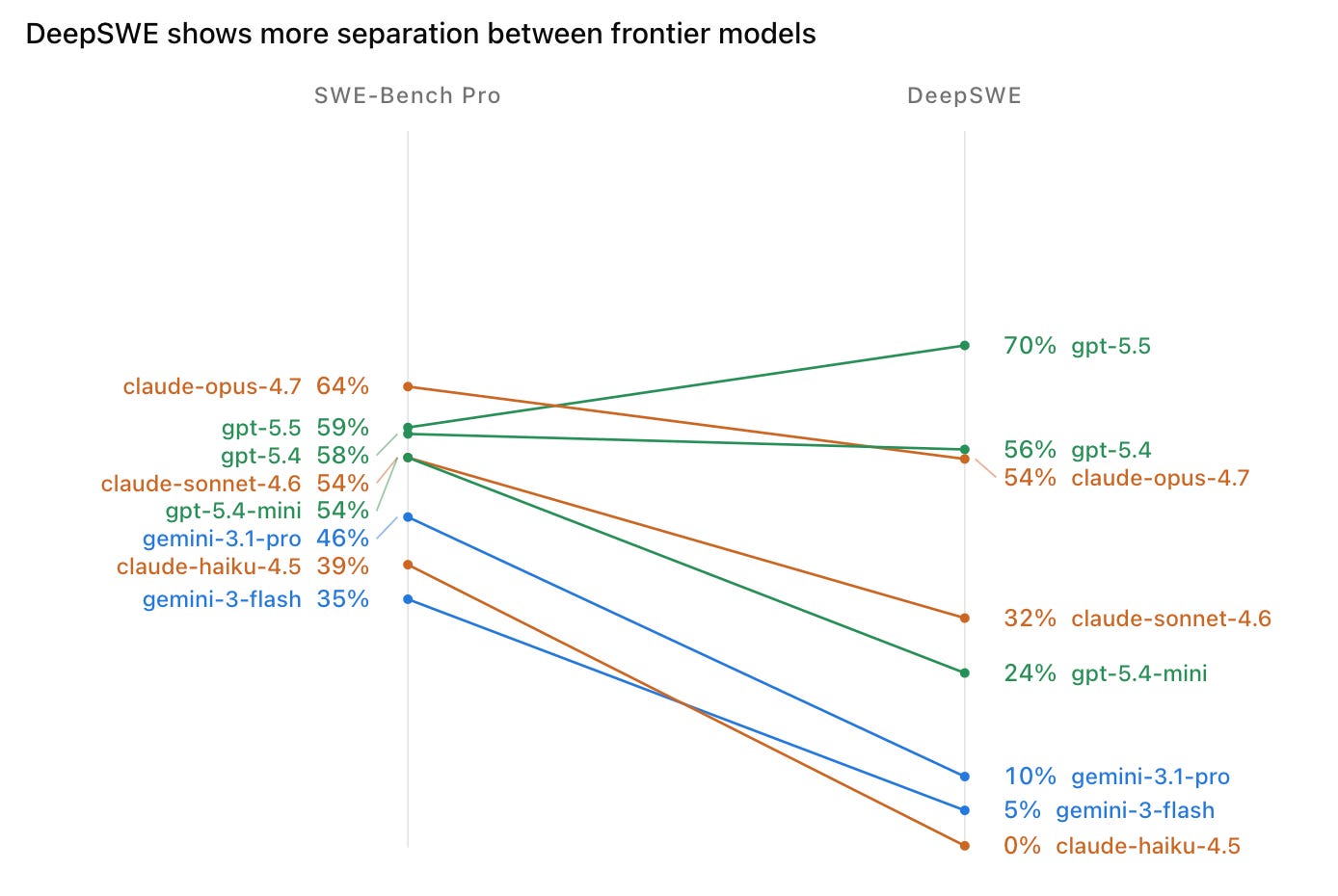
The practical results here are rather striking versus what typical benchmarks show when comparing models. GPT 5.5 is clearly the leading coding model today, with Opus being the second best. The gap between the two was minor by the end of last year, when Claude Code became widely adopted due to user preferences, but GPT 5.5 has changed things and this has been obvious to most power users as sentiment has shifted on X. Google models are essentially useless for agentic coding on novel problems, and this has been the case for a while.

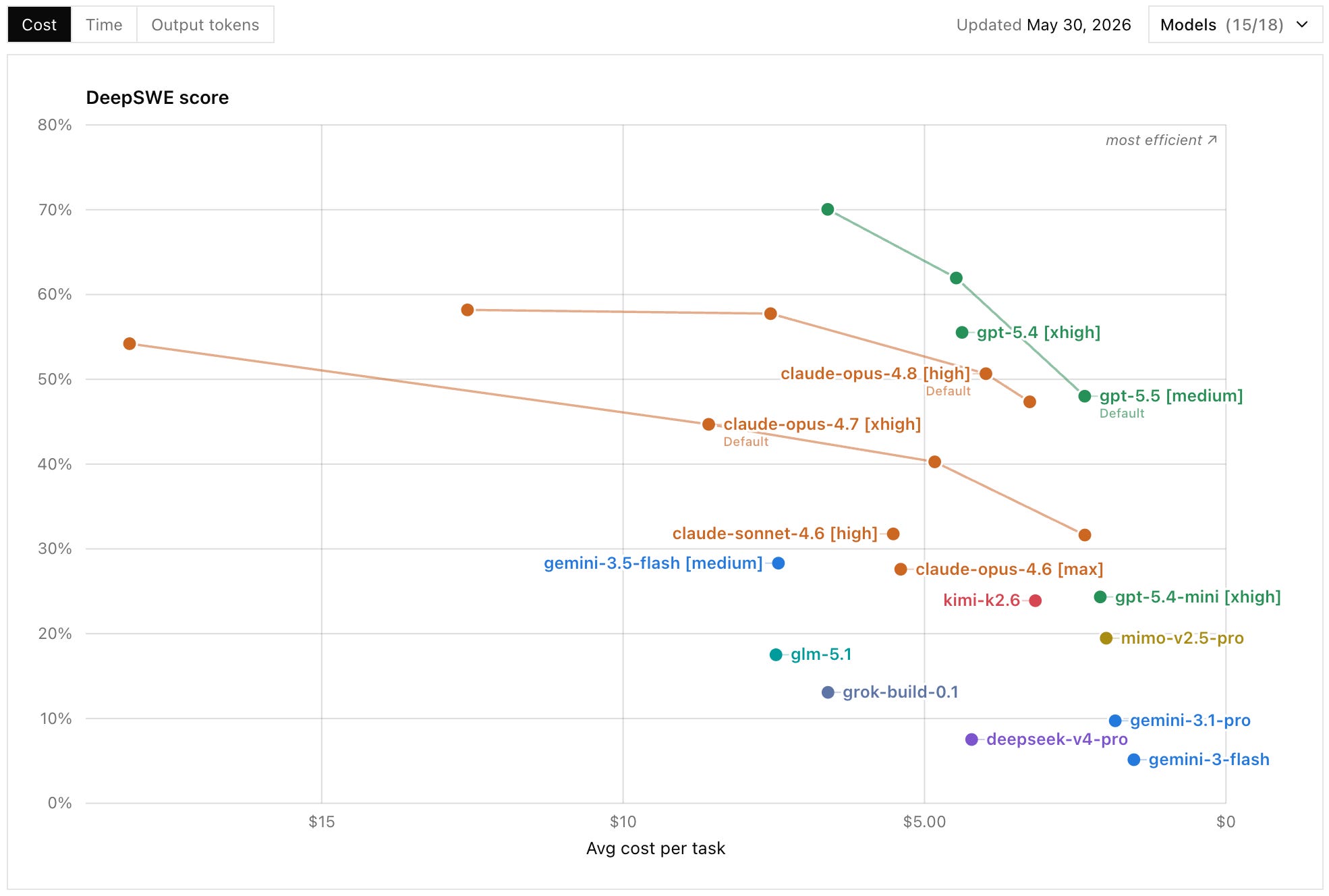
If we visualize this in terms of both performance and cost, the lead here for GPT 5.5 (xhigh) is significant. It’s both cheaper and more effective than Opus 4.8, which is a minor improvement in efficiency versus 4.7.
What’s also interesting is how poorly open-source models or alternatives from Google and xAI are performing on these evaluations. While we shouldn’t be too negative about their performance, they are clearly one to two releases behind the two leading labs and very much not a cost-efficient choice. The Gemini 3.5 Flash fiasco speaks for itself: it released a model that is half as effective in coding tasks as Opus 4.8 on high, while consuming almost double the tokens in dollar value.
Infra Play #146: The state of cloud infrastructure software

The biggest story in software five years ago was the shift of value from the application layer toward cloud infrastructure software. The biggest story today is the merging of applications and infrastructure in the new computing stack, which we refer to as AI but which is in practice the move from utility to intelligence.
The notable missing player here is Cursor with Composer 2.5 since the model is only available in the Cursor harness and not via API. It’s also important to note that a better coding model doesn’t automatically translate to higher revenue performance, as Anthropic is currently killing it in terms of GTM execution with enterprises versus OpenAI, regardless of what the “terminally online” see in their own usage.